fecify 采集alibaba
alibaba.com国际站,B2B平台,将商品数据采集到fec ify独立站,支持商品多语言数据采集
采集alibaba - 配置
一:配置
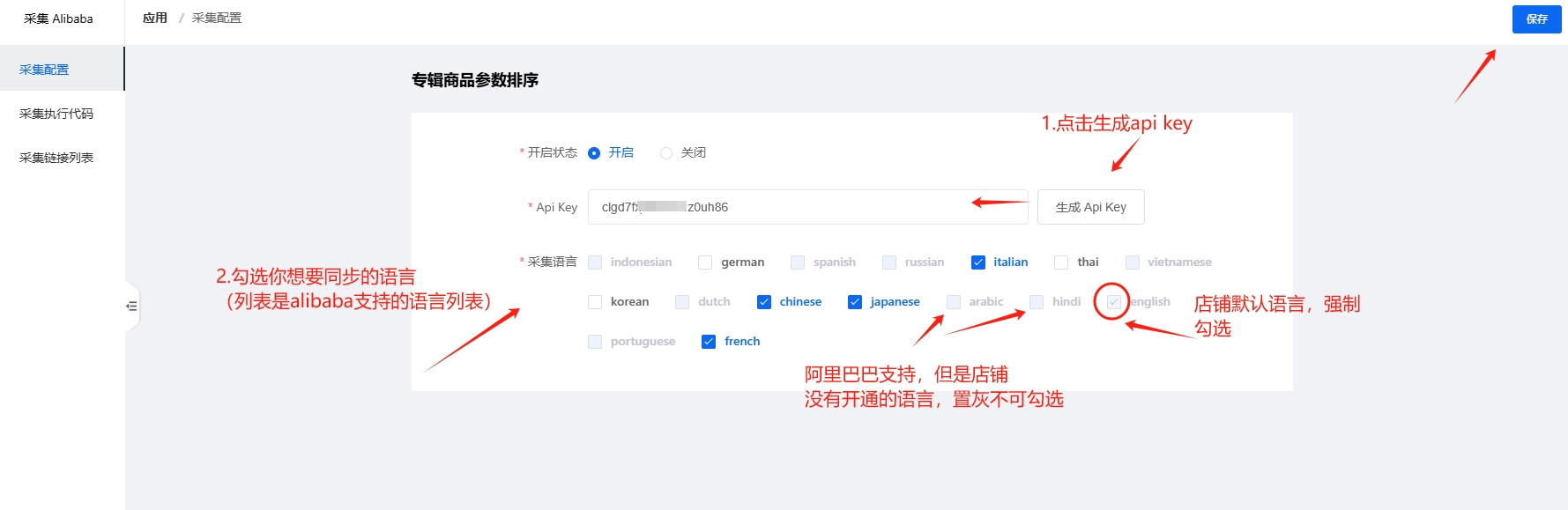
1.如果您想要采集多语言数据,您需要先进入多语言插件添加多个语言,然后设置店铺的默认语言
- 店铺默认语言设置后,后面就不要改动了,否则可能会导致采集失败
2.配置
二:浏览器下载篡改猴
1.使用chrome浏览器,访问网址:https://www.tampermonkey.net/?locale=zh
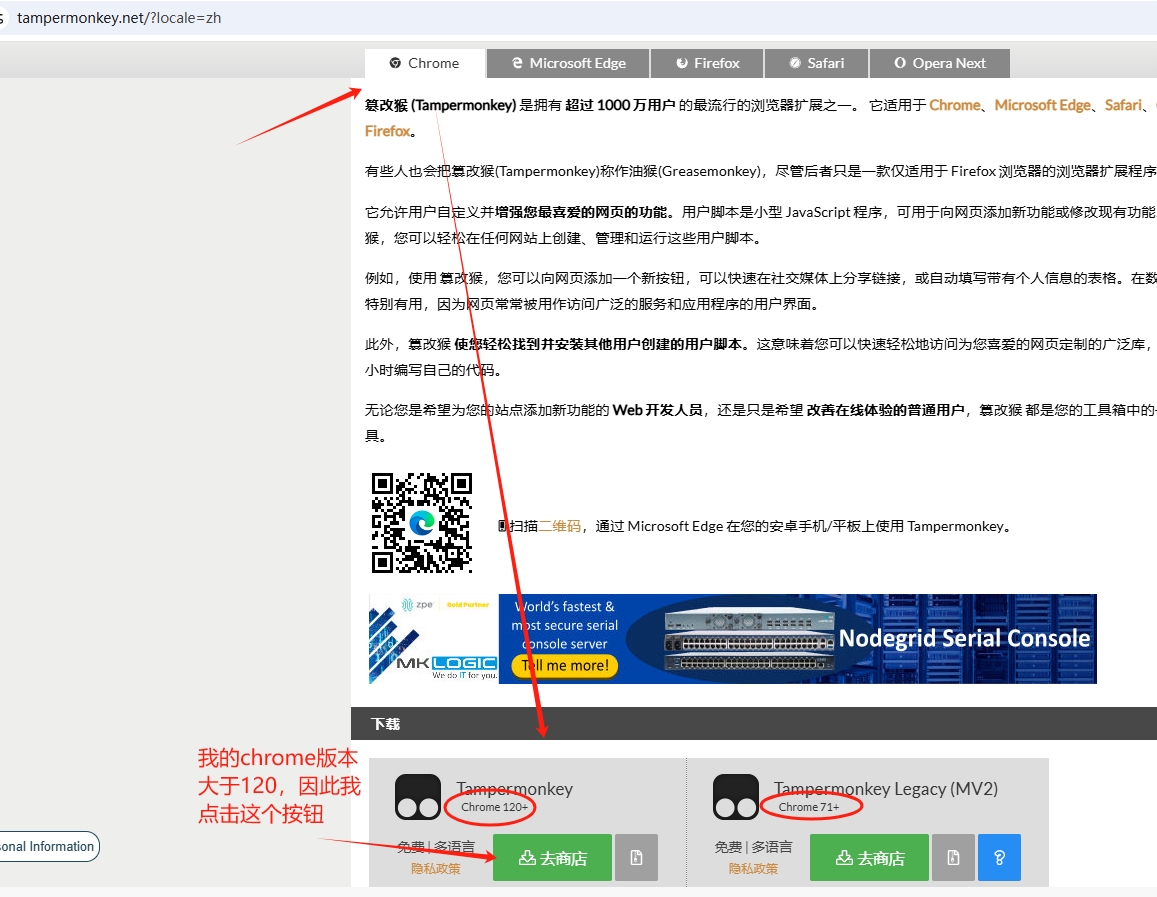
2.点击绿色按钮后,进入篡改猴插件安装页面,安装即可
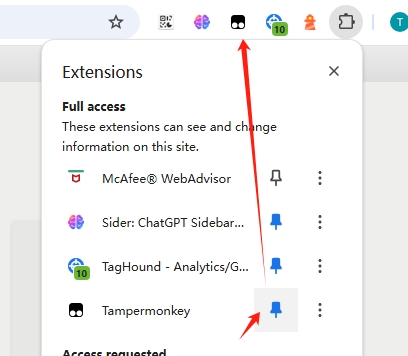
3.安装之后,可以点击下面的图标,点击后,就会订在顶部
4.进入商家端后台,复制代码
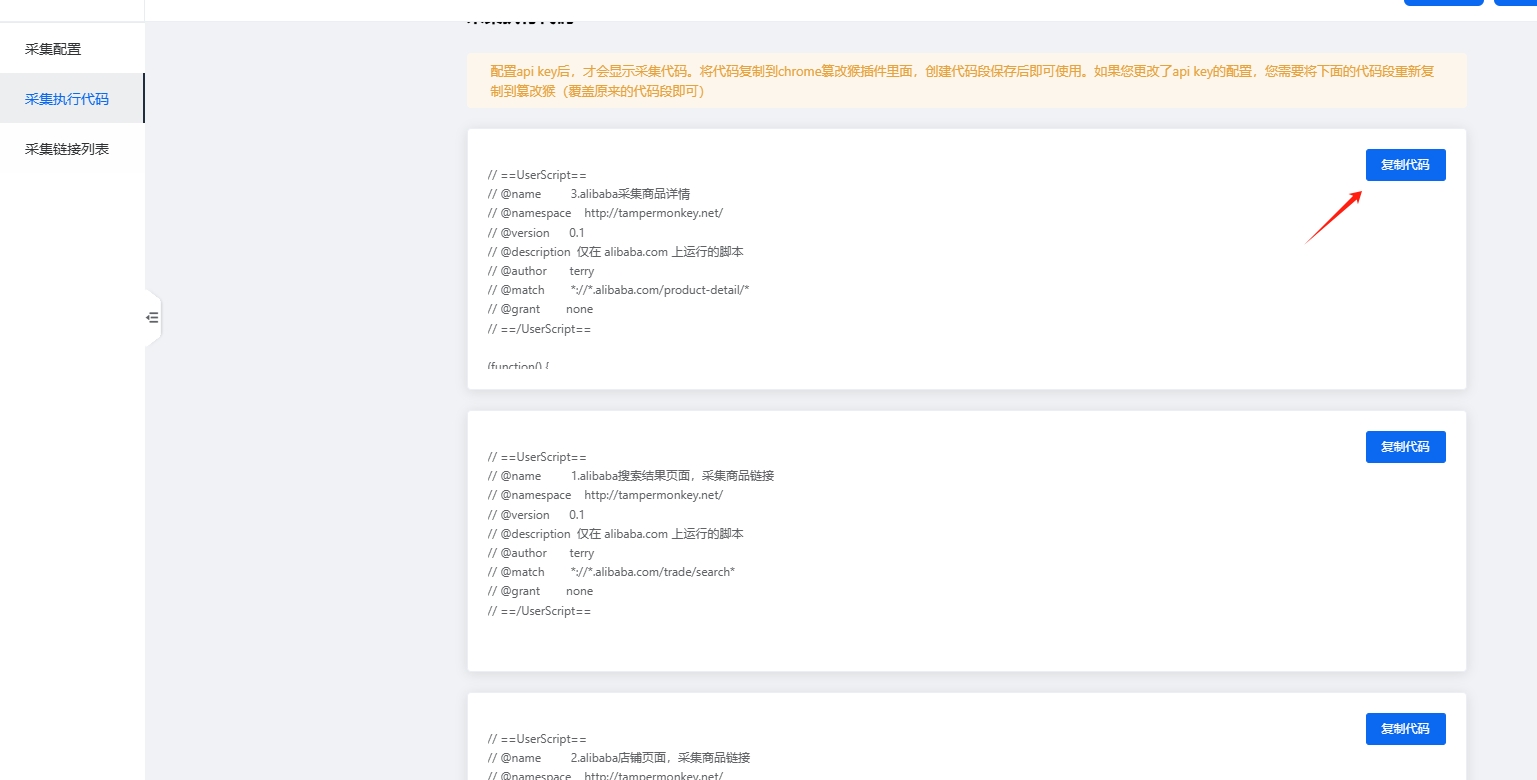
5.创建代码脚本
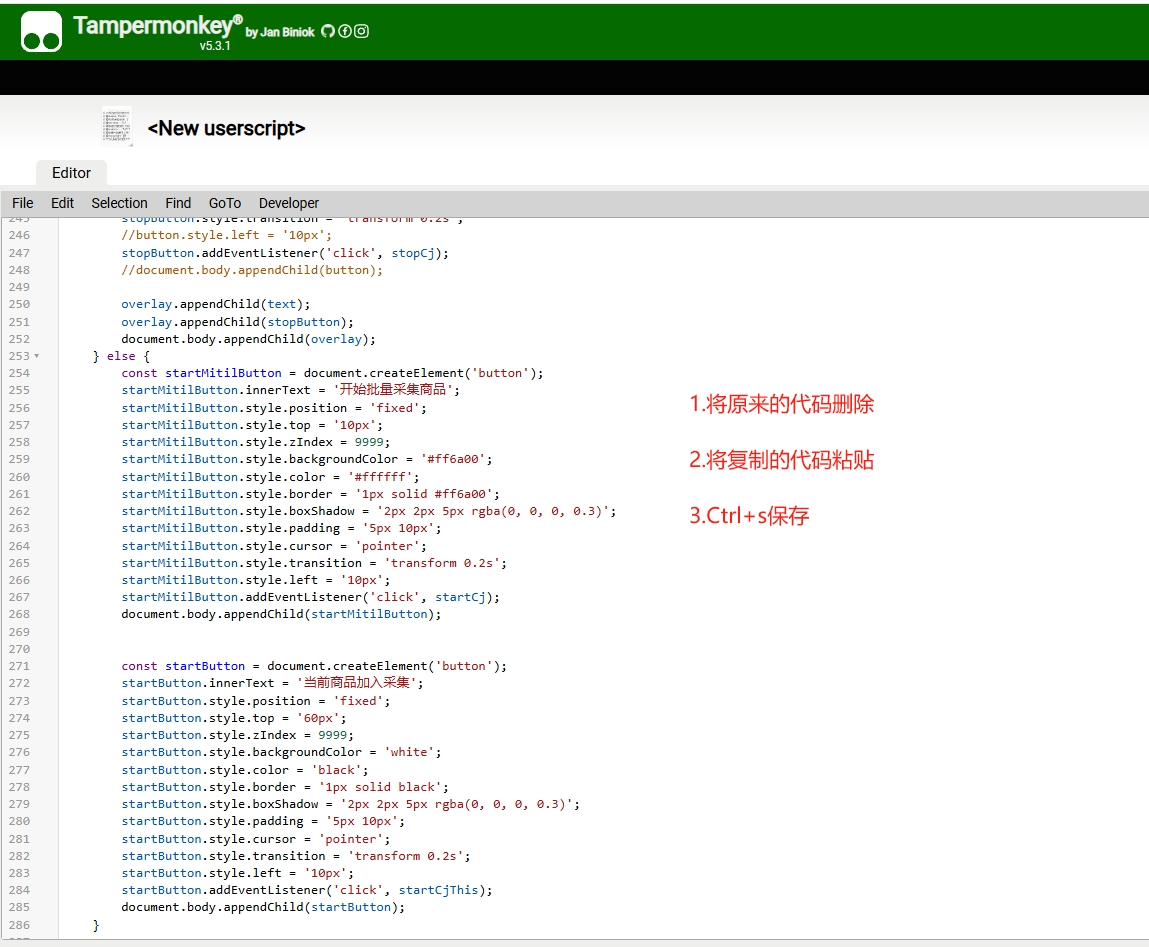
将第4步骤复制的代码,粘贴到篡改猴,保存
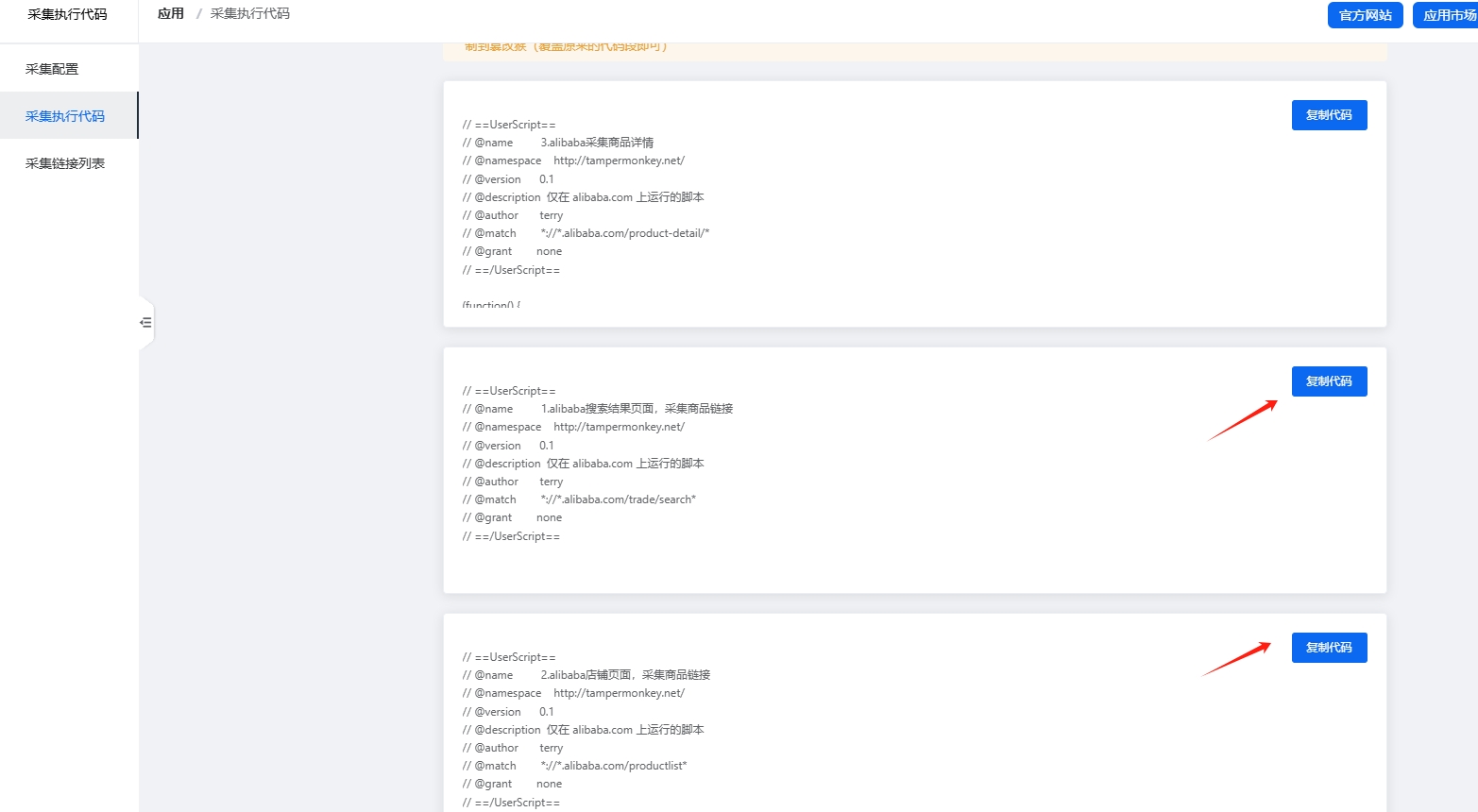
6.粘贴下面的2个代码段,重复上面的操作
完成后,如下图,一共3个脚本
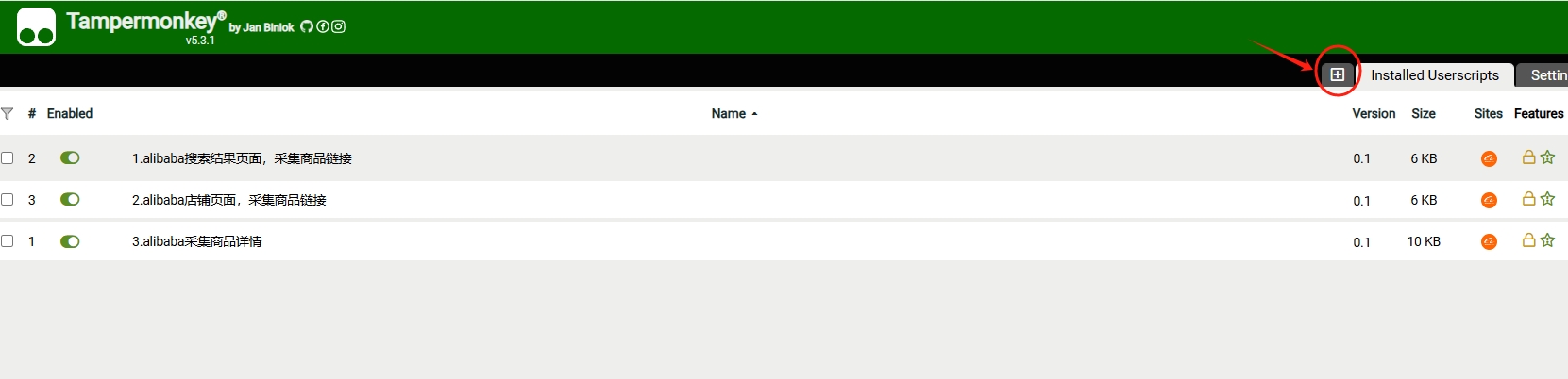
到这里,我们在篡改猴这里创建了三个脚本
7.chrome需要开启开发者模式
开启Chrome开发者模式的步骤
- 打开Chrome浏览器,点击右上角的菜单按钮(三个垂直点)。
- 在下拉菜单中选择“设置”。
- 进入设置后,点击“扩展程序”。
- 在扩展程序页面,点击右上角的“开发者模式”按钮即可开启。
!!!!这个一定要开启chrome开发者模式,否则脚本将无法运行!!!!
!!!!这个一定要开启chrome开发者模式,否则脚本将无法运行!!!!
!!!!这个一定要开启chrome开发者模式,否则脚本将无法运行!!!!
三:进行采集: 商品url链接
商品的采集,是分为2个步骤
- 先进行商品url的采集
- 通过商品url链接表数据,依次采集商品的多语言数据
1.搜索结果页面,采集链接
进入alibaba,搜索一个关键词
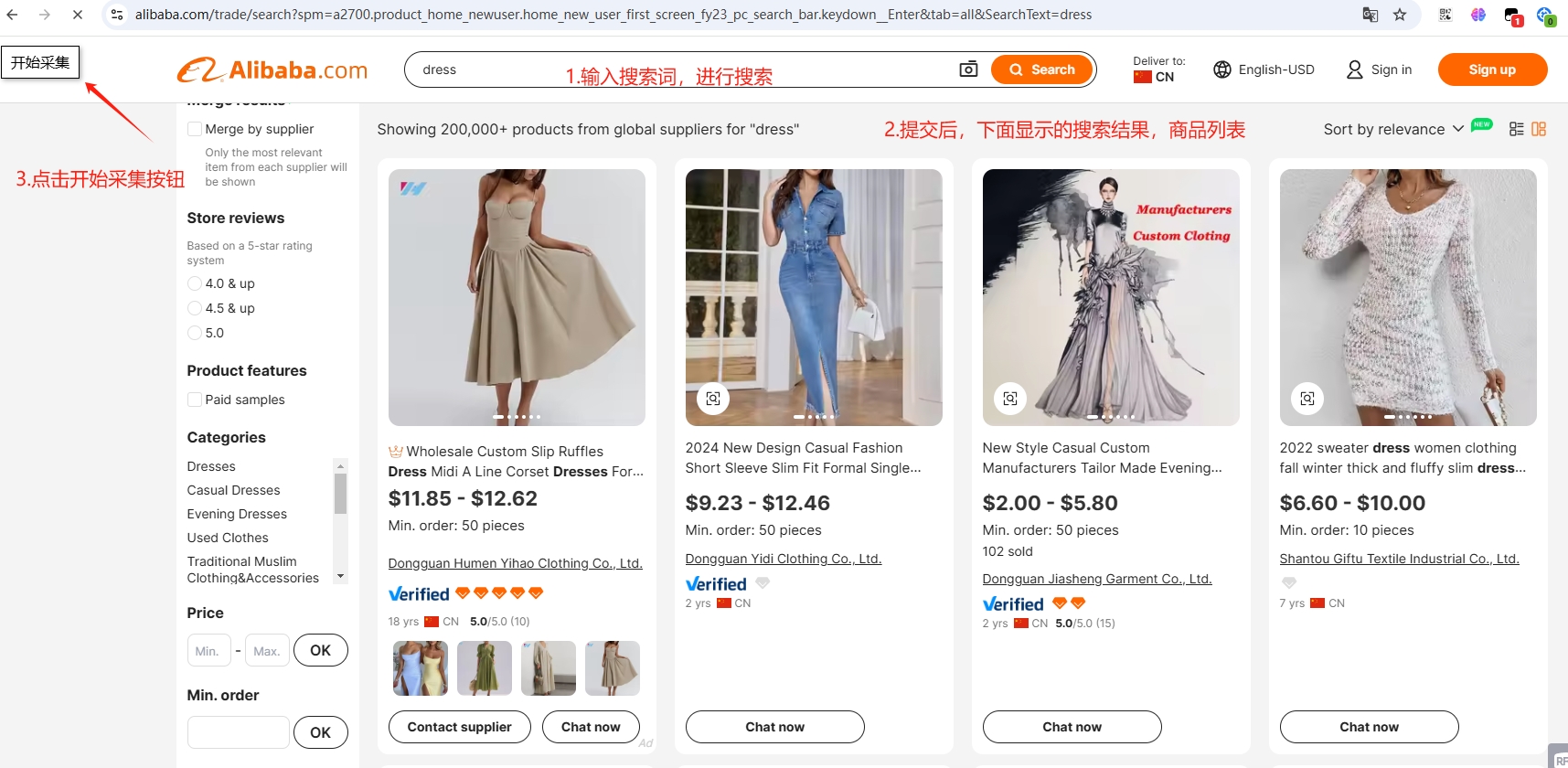
进行商品链接的采集,这个过程中需要保持网络的畅通,电脑尽量少开软件,浏览器将其他的tab都关掉,节省资源,以免浏览器卡掉
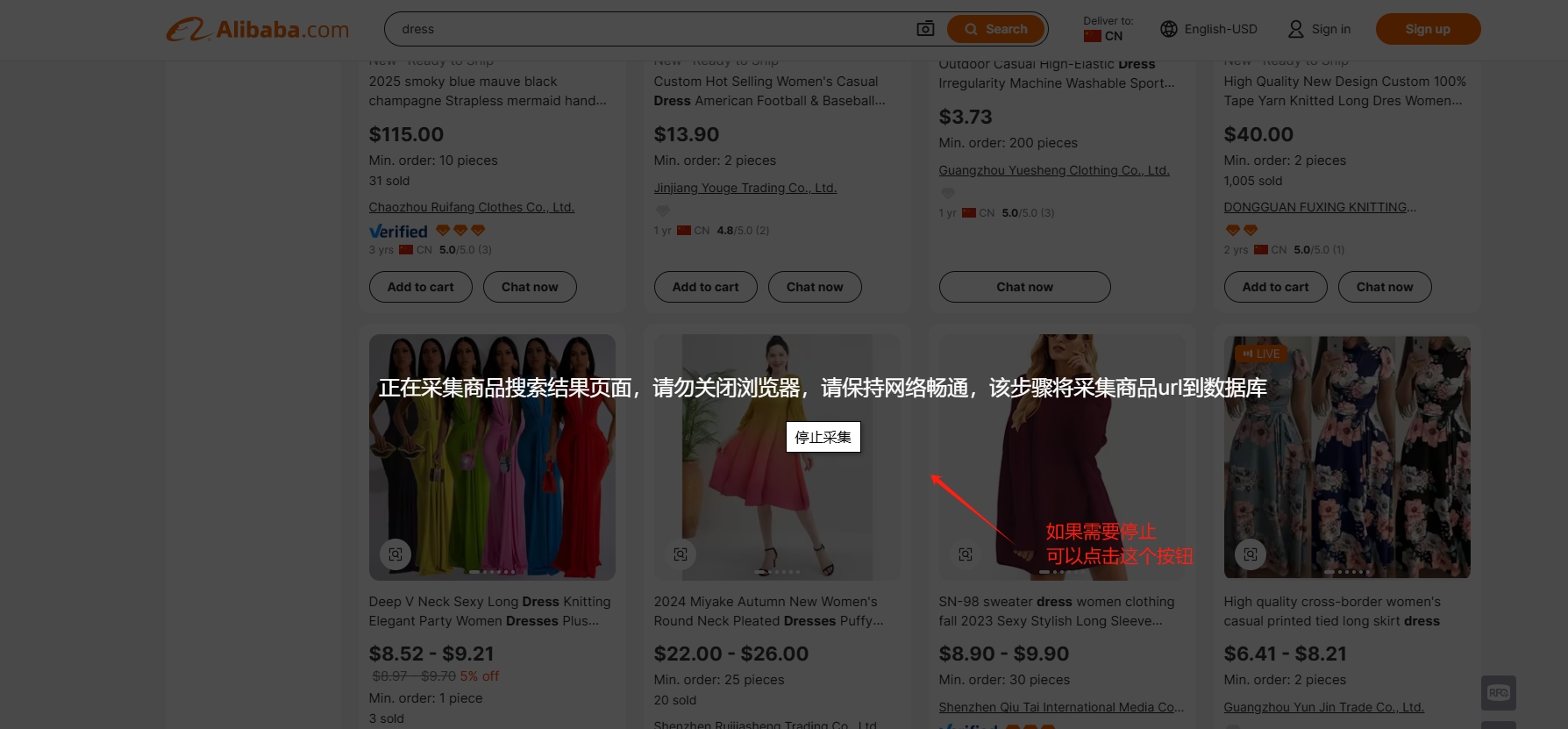
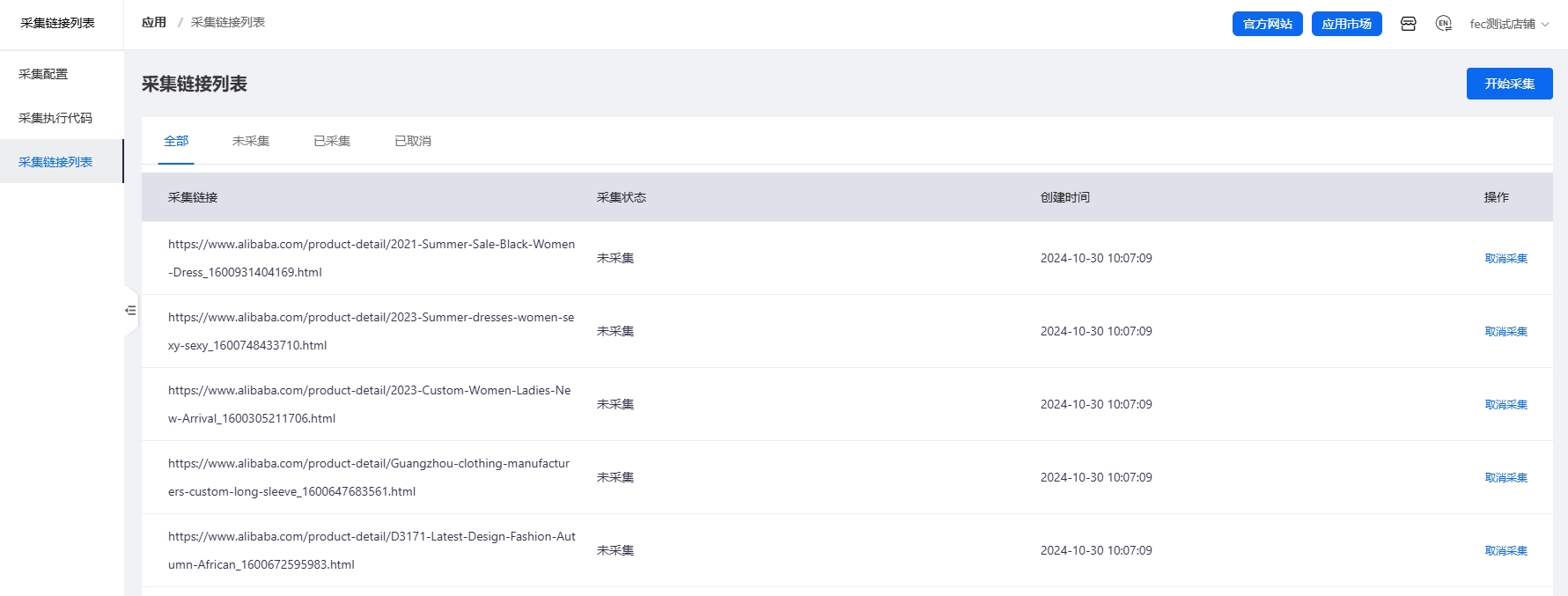
采集完成后,可以在商家端后台,查看采集后的商品链接url
2.店铺采集商品url链接
- 进入一个alibaba的店铺,然后采集这个店铺的所有商品
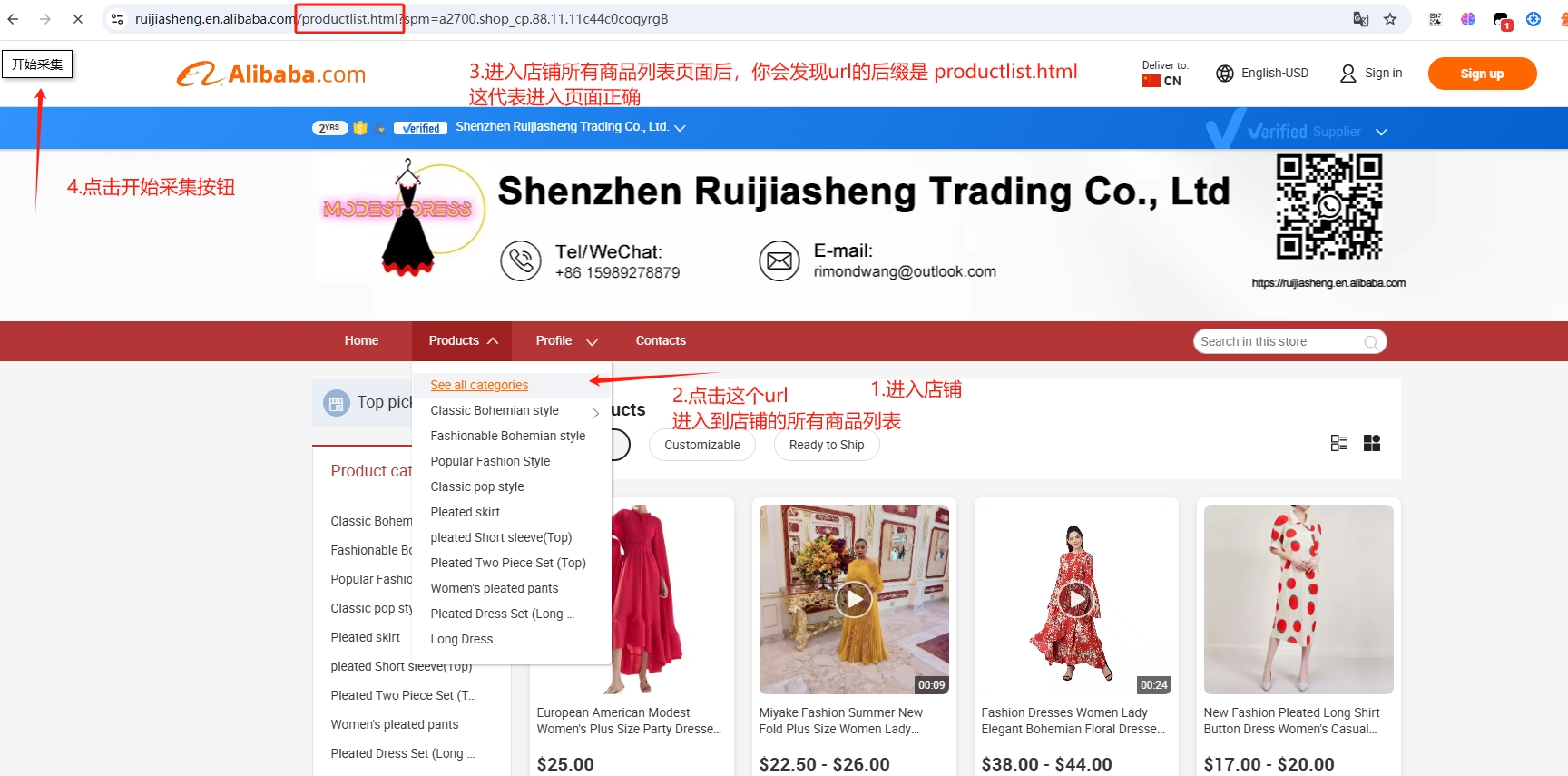
点击开始采集按钮后,可以在商家端后台,查看采集后的商品链接url
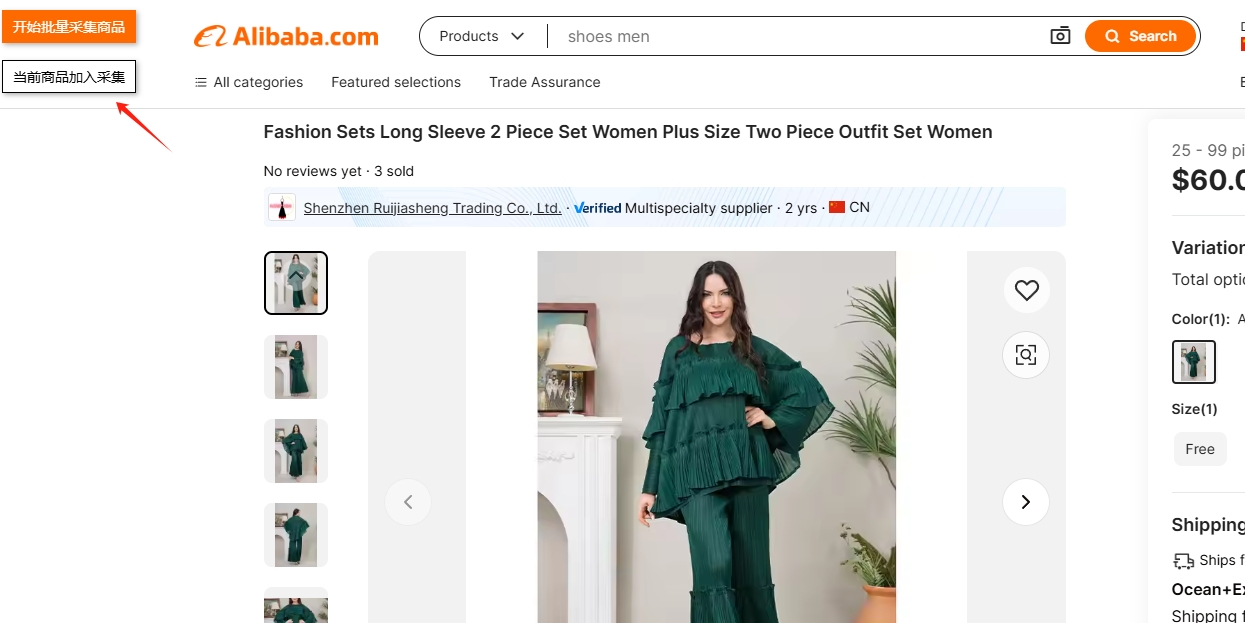
3.商品详情页,单个商品url链接采集
进入商品详情页,点击按钮:当前商品加入采集
点击开始采集按钮后,可以在商家端后台,查看采集后的商品链接url
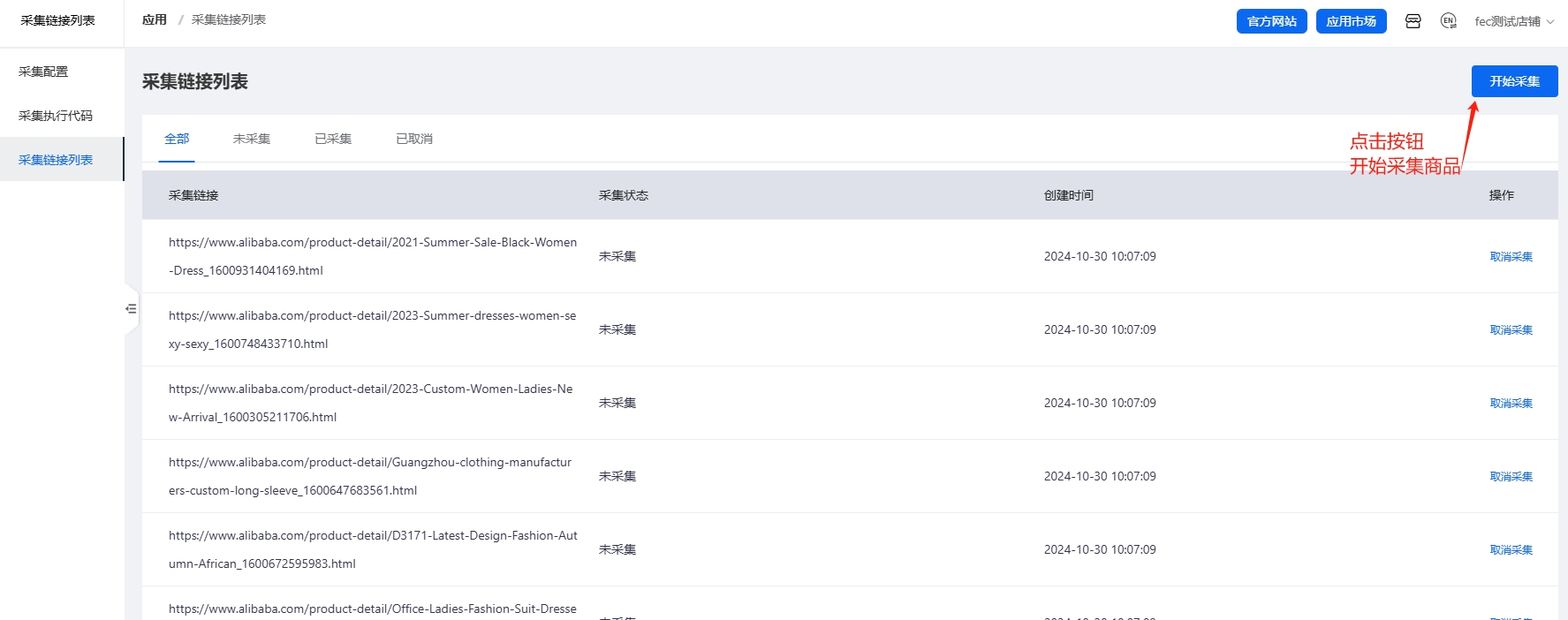
四:采集商品
商品url采集后,可以在商家端后台,查看采集后的商品链接url
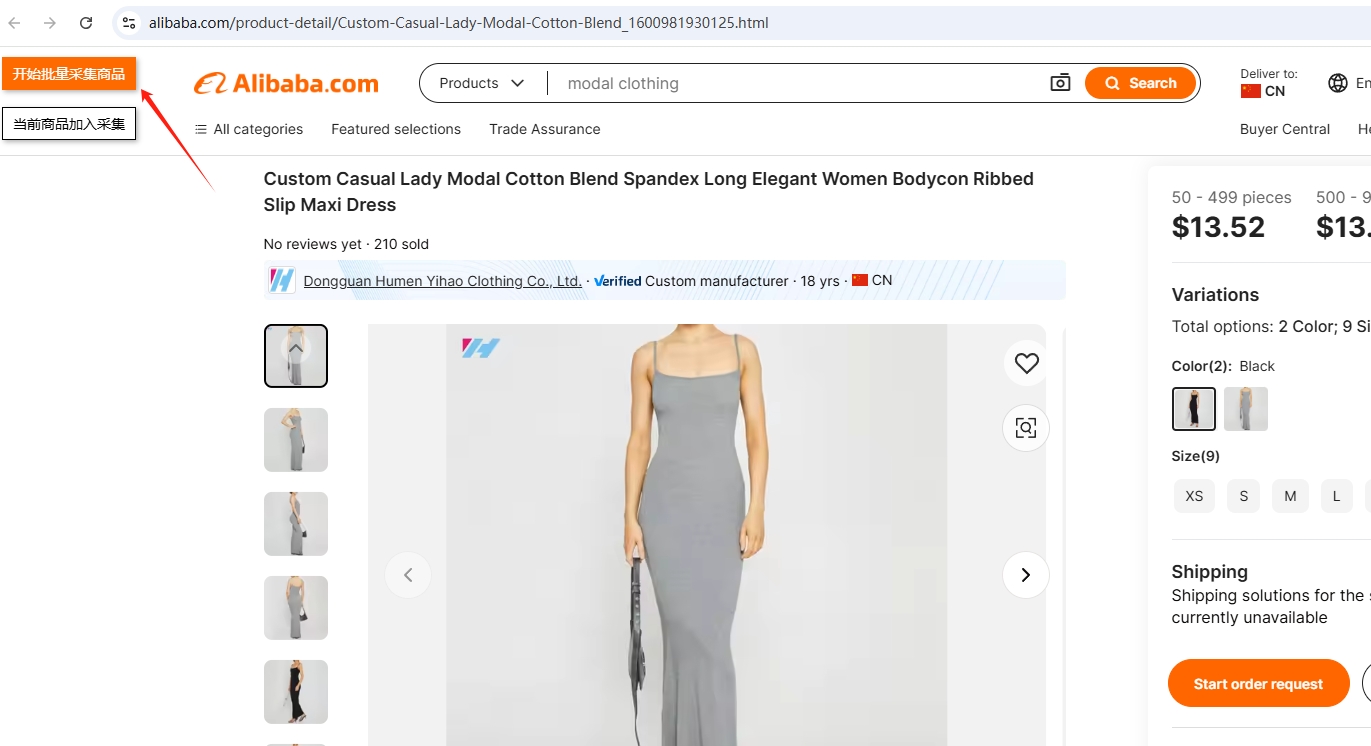
点击后,在浏览器的新tab中打开一个alibaba的商品详情页(列表中必须有未采集的url链接才行),然后点击黄色按钮:开始批量采集商品
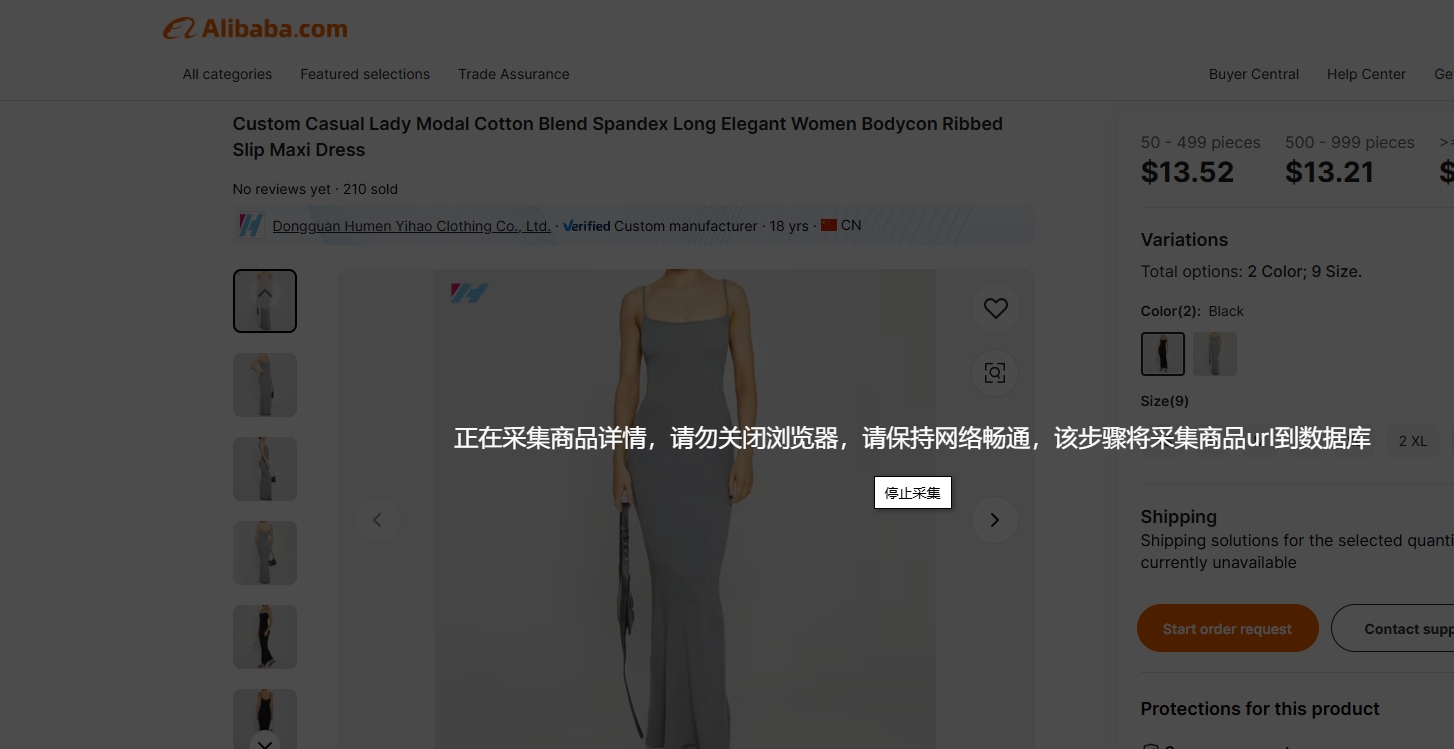
点击后,进入商品采集逻辑
- 每个商品,依次执行采集逻辑
- 按照配置的多语言,每个商品的每个语言都将被访问采集
- 请保持网络畅通,尽量关掉其他的软件,保持电脑资源畅通,以免卡死影响采集
- 浏览器需要一直打开,不要关闭,不要最小窗口化,让该窗口一直保持运转状态。
- 您的电脑不要设置超过x分钟后休眠,让电脑一直保持运转状态
- 您可以泡壶茶,一边喝茶,一边等待采集
可以在商家端后台,商品管理部分,查看采集后的商品列表
五:问题
1.如果您在浏览器操作多个f ecify独立站店铺,进行采集alibaba,每个独立站的采集脚本是有差异的,您需要将A独立站的油猴的三个脚本状态disable掉,然后 按照上面的步骤,添加脚本,然后才可以进行采集。